
I ran a small GenAI teaching experiment last week, asking 9 groups of South African executives to develop detailed customer personas for a finance product through dialogue with Anthropic’s Claude LLM. The results were genuinely interesting, and some groups were able to achieve a detailed persona, communication guidelines, an outline marketing strategy and even ideas about where to advertise to attract the defined buyers in about 40 minutes. It was all about the prompting, and working around the limitations of the training data when it comes to Africa. Interesting, eye-opening, and efficient – at least an order of magnitude faster than traditional workshop methods.
Nobody’s job was replaced, but everyone could see the potential for lightly automating various aspects of customer strategy and making up for the lack of a single source of customer truth by having GenAIs synthesise and summarise multiple sources of customer interaction data in close to real-time. Simple. Useful. An indication of many other little helper tasks that could be part of wider use cases in the enterprise.
AGI or bust?
Meanwhile … the soap opera around OpenAI and the future of Artificial General Intelligence (AGI) continues to waste valuable thought cycles and pixels.
Before yesterday’s “news” that several senior people are departing OpenAI, Ed Zitron wrote a long piece predicting the company’s collapse, due to its incredible capital and data requirements but lack of a clear business model:
I ultimately believe that OpenAI in its current form is untenable. There is no path to profitability, the burn rate is too high, and generative AI as a technology requires too much energy for the power grid to sustain it, and training these models is equally untenable, both as a result of ongoing legal issues (as a result of theft) and the amount of training data necessary to develop them.
The risks for OpenAI as a company are even greater now that open source models such as Llama 3.1 are catching up with closed source models like ChatGPT. Meta has also spent a lot of money getting Llama to that position, but their strategy of commoditising their complement is smart and de-risks the rise of a single closed source model like ChatGPT.
But with so much money chasing what could be a game-changing technology, it is no surprise that there will be over-investment, over-capacity and some big losses for the early worms, as with previous big shifts in computing. For a more mature historical view on this phenomenon, and a caution against retail investors taking Nvidia positions (particularly relevant this week of all weeks!), Larry Dignan’s piece in the Constellation Research newsletter is worth a read.
Gary Marcus continues his crusade against LLMs as a form of intelligence, arguing that they are doomed to fail when presented with outliers, which poses real challenges for Tesla’s autonomous driving strategy and other use cases for neural networks trained on past data.
The people who have temporarily gotten rich or famous on AI have done so by pretending that this outlier problem simply doesn’t exist, or that a remedy for it is imminent. When the bubble deflation that I have been predicting comes, as now seems imminent, it will come because so many people have begun to recognize that GenAI can’t live up to expectations.
The reason it can’t meet expectations? Say it in unison, altogether now: GenAI sucks at outliers. If things are far enough from the space of trained examples, the techniques of generative AI will fail.
Instead, Marcus argues that a neurosymbolic approach is needed, which would be slightly closer to biological intelligence:
The idea is to try to take the best of two worlds, combining (akin to Kahneman’s System I and System II), neural networks, which are good at kind of quick intuition from familiar examples (a la Kahneman’s System I) with explicit symbolic systems that use formal logic and other reasoning tools (a la Kahneman’s System II).
This idea of mimicking biological intelligence was also echoed in another recent warning about LLMs, this time from John Thornhill in the FT, writing about the risk of model collapse, where LLMs become sick because of synthetic content being recycled from outputs into training data:
When I interviewed the cognitive scientist Alison Gopnik earlier this year, she suggested that it was the roboticists who were really building foundational AI: their systems were not captive on the internet but were venturing into the real world, extracting information from their interactions and adapting their responses as a result. “That’s the route you’d need to take if you were really trying to design something that was genuinely intelligent,” she suggested.
Of course, building a model and understanding of the physical world is a necessary precursor to real intelligence, and this will be one of the layers in the AI stack that can add value to basic components like LLMs.
But I am sure there are plenty of smart people working on this long-term goal, so perhaps the rest of us can come back down to earth for a moment and focus on the very real, immediate benefits of using the pseudo-AI we already have to automate and synthesise information, with humans (or cats, or crows, whatever…) bringing the intelligence and world knowledge to apply it.
Smol things
Even with LLMs, the smaller and more bounded the domain they work in, the better their results will tend to be. GenAI company Writer last week announced two new Small Language Models (SLMs) for medicine and finance, with impressive benchmarks, which they hope will be used as the basis for AI apps in those areas:
Domain-specific LLMs will be at the forefront of AI innovation, transforming how industries build specialized AI applications. Writer is pioneering this movement by creating models like Palmyra-Med and Palmyra-Fin — models with deep, sector-specific expertise, exceptionally well-suited for enterprise use cases.
The goal of Fabric is to provide a simpler, more intuitive way to interact with LLMs, making it easier for developers and researchers to build applications and conduct experiments with these powerful models.
It does this by providing many complex, fully formed prompts that can be fed into large Language Models to help get the best answers possible to questions. In addition, Fabric comes with several helper apps that can,
- Simplify LLM interactions
- Promote the reusability of prompts and templates
- Enable complex workflows through chaining
- Provide a consistent interface for various LLM-related tasks
And there are plenty of small examples being shared – similar to the teaching story I shared above – about automating existing workflows using GenAI and related tools, such as this tweet by Paige Bailey.
From components to products & systems
I think of LLMs and especially SLMs as a kind of equivalent of libraries and functions in software, which we will lean on heavily as components that help us build higher level applications. But we are still finding our way towards categorising the various AI-related tools that are emerging, and we do not yet have smart development tools that can combine these components with other systems and services, knowledge stores and people-managed processes to create high level AI-enhanced apps – something like an IDE for AI-enhanced use cases and capabilities.
On the mapping question, the ever-insightful Matt Webb has shared some thoughts on how to map the emerging landscape of gen-AI product user experience, showing how different products combine different modes of AI activity in different ways. It’s an interesting “scaffolding for the imagination” as Matt concludes.
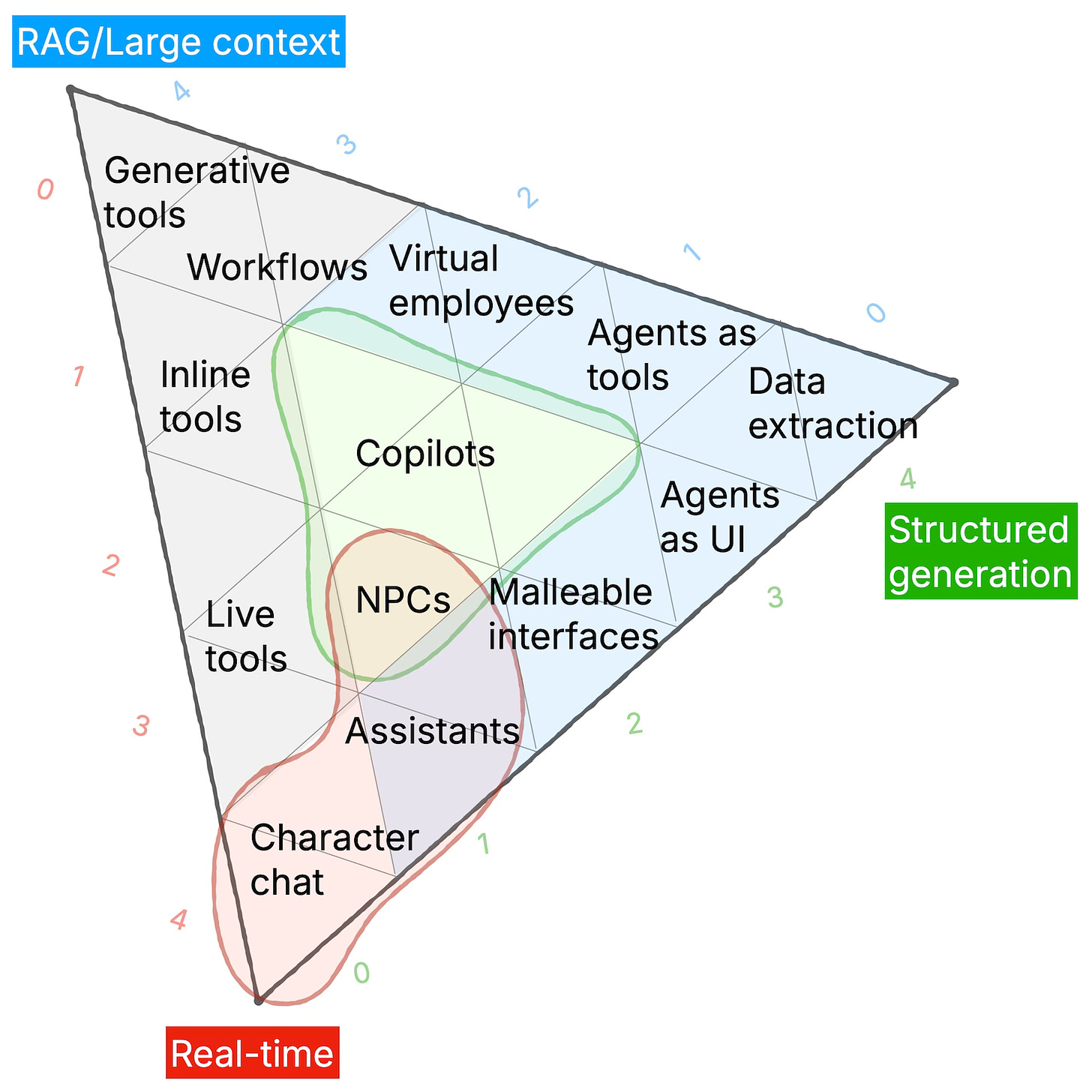
AI Products Map by Matt Webb.
Aside from the nature of AI-related products and the interface types they might use, there is the wider question of adoption and what used to be called ‘change management’. That is why it can be so powerful to show and tell within a specific business context, rather than teach this stuff in the abstract.
In Seven hard truths for CIOs to get from pilot to scale, McKinsey argue that the main investments needed for enterprise AI will be people and change-related:
Our experience has shown that a good rule of thumb for managing gen AI costs is that for every $1 spent on developing a model, you need to spend about $3 for change management. (By way of comparison, for digital solutions, the ratio has tended to be closer to $1 for development to $1 for change management
We continue to develop our framework for breaking down AI-enhanced capability goals into the various technical and non-technical components, which is a very practical way to get a handle on what is needed to address real use cases within the enterprise. And we are finding new ways to build this capability lens into our leadership development work and executive education in general.
Take a look at what we can offer your organisation and maybe consider inviting us in for an informal talk to inspire your colleagues.